
Mängden data och möjligheterna med dataanvändning växer exponentiellt och organisationer investerar stora summor i teknologi och mjukvara för att fånga in data som ska leda till insikter och bättre beslut. Men insikterna och besluten blir aldrig bättre än den data som analyseras. Mer data ökar risken att ha dålig och ej användbar data som bland annat leder till ökad administration, längre svars- och ledtider, säkerhetsproblem, högre kostnader och minskad tilltro. Företag kan ösa in pengar på teknik men om inte mekanismerna finns implementerade för hur data ska hanteras så kommer man med största sannolikhet inte förflytta sig framåt i sin digitala transformation. Detta är ett stort problem för många organisationer. I detta blogginlägg beskriver vår expert Henry Korpela Governance och Data Lifecycle Management (DLM) som två viktiga områden för att undvika ”Bad Data”.
”Big data” avser egentligen de stora och olika mängder data (information) som ökar i allt snabbare takt. Det omfattar data-volymen, hastigheten (velocity) med vilken den skapas eller samlas in och variationen av datainsamlingspunkter som används, mer känt som de tre V:na (investopedia.com). I detta inlägg avses inte bara ”Big Data” utan data i en mer omfattande betydelse.
”Bad Data” eller dålig data är egentligen data som är oanvändbar i sitt nuvarande tillstånd. Med dålig data menas data som är ostrukturerad, rå eller inte möter de kvalitetskrav som har ställts upp men också data som är felaktig, saknad, duplicerad eller rentav olaglig. Datakvalitet brukar mätas i vanligtvis sex olika dimensioner – completeness, uniqueness, timeliness, accuracy, consistency och validity.
Rapporter har visat att så mycket som 20 % av ett företags data är felaktig, vilket i förlängningen orsakar negativa effekter på affärsresultatet. Gartner, till exempel, estimerar att företag i snitt förlorar ca. 130 miljoner kronor årligen på grund av dålig data. Det finns både strategiska och organisatoriska utmaningar att ta vara på potentialen som mer data erbjuder. En Gartner-undersökning från 2017 lyfter fram följande bild där följande fråga ställdes: Vilka är din organisations 3 största utmaningar med att använda data och analytics?
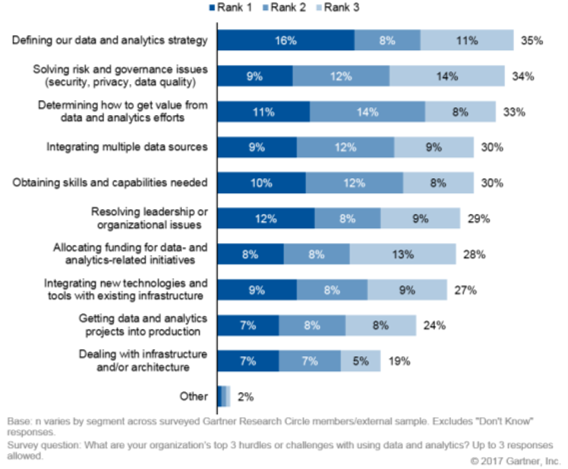
Vi kan utläsa att organisationer har svårt och ser det som prioriterat:
- att definiera en gemensam strategi för data och analytics
- att lösa ledarskap och organisationsproblem
- att bestämma hur man ska få ut värde från sina data- och analytics-ansträngningar
- att lösa (data)problem relaterade till risk och governance (säkerhet, integritet och datakvalitet).
Det är inte bara teknologi som är viktigt för att säkerställa bra data av hög kvalitet utan lika mycket är det de strategiska och organisatoriska frågeställningarna som möjliggör att organisationer kan bli mer datadrivna. Jag vill speciellt lyfta fram dessa två områden som viktiga möjliggörare; (Master) Data Governance och DLM (Data Lifecycle Management).
Data Governance
Governance kan kort förklaras som sättet organisationen styr och hanterar sina processer och (master)data. En väl utvecklad governance-modell ska innefatta organisationens huvudprocesser (oftast de tvärfunktionella) med roller och ansvar för process och data på både strategisk och operativ nivå. När ägarskapet över processer och dess data tydliggörs då blir det mycket lättare att:
- bestämma hur datalivscykeln ska hanteras och vem som bestämmer hur data ska skapas, uppdateras (ändras), läsrättigheter och slutligen raderas. Här kan en RACI-modell vara användbar.
- höja datakvaliteten och vilka som har det yttersta ansvaret för att ”tvätta” data (cleansing)
- sätta regler, format och standard på data
- veta vem som bestämmer vad som är en ”good enough” datastandard.
DLM (Data Lifecycle Management)
Oftast ser vi data som det som flyter mellan systemen, det vill säga blodet i processerna som får verksamheten och de olika systemen att fungera. Men hur data skapas, används, uppdateras och till slut arkiveras och raderas behöver definieras. Lägg därtill säkerhetskrav och lagringskrav så blir det en komplex modell. DLM är en modell eller process för att hantera livscykeln för data med målet att optimera dataanvändningen. Som vanligt finns det olika skolor för vad som ska ingå i DLM. En bra bas är att tillämpa CRUD (Create, Read, Update, Delete). Lägg därtill säkerhet och lagring så har du täckt stora delar av de komponenter som bör ingå.
Att implementera ett DLM-ramverk kan ge organisationen ytterligare fördelar, exempelvis:
-
Hjälper dig att följa reglerna och kraven för lagring av uppgifter. Varje bransch har sin egen reglering av data. Det finns också lokala eller regionala lagar för att skydda personuppgifter som kan gälla.
-
Garantera effektivitet. Du har tillgång till relevant information vid rätt tidpunkt. När du implementerar DLM ställer du in standarderna för att automatisera validering, anrikning och integrering av data.
-
Erbjuder säkerhet. I alla stadier överväger du de säkraste sätten att hantera data. För datalagring skapar du också beredskapsplaner i händelse av en nödsituation.
Sammanfattningsvis...
Att ha en governance- och DLM-modell säkrar kvalitetsdata – och säkerställer dess integritet – vilket gör data till en mycket mer värdefull tillgång för din organisation.

